드디어 논문을 투고합니다.
저는 학부생이고 인연처럼 연구실에 들어갔다가 저널 투고의 경험을 맛보게 되었습니다.
이 블로그 글에서는 제가 논문을 투고하는데까지의 과정을 남겨보겠습니다.
저는 기존에 강화학습을 이용해서 충돌 회피 알고리즘을 만들어 본 경험이 있고, 이 과정을 담아 2페이지 학술지를 ICROS 학회에 제출하여 포스터 발표를 하고 왔습니다.
논문 주제 선정:
기존 ICROS 학회에서 발표한 제 학술지는 저가형 근접센서를 활용한 충돌 회피 알고리즘입니다. 이 내용을 연장선으로 두고 강화학습을 이용한 충돌 회피에 좀 더 깊이 있는 연구가 해보고 싶었습니다.
약 2016년 부터 Curriculum Learning (CL) 을 Deep Reinforcement Learning (DRL) 에 적용하면서 학습 속도, 보상 희소성 등 강화학습에서 발생하는 문제점들을 개선할 수 있었습니다. CL은 인간이 학습하는 과정에서 비롯되어 적절한 커리큘럼을 설계하여 특정 작업을 학습시키는 방법입니다. 인간이 학습하는 과정과 너무도 비슷하고 직관적이었던 이 개념은 저에게 흥미롭게 다가왔습니다.
전반적인 개요 작성:
논문을 작성하기 전에 가장 먼저 해야될 것은 일정과 틀을 잡는 것입니다. 정말 형편없이 대충 세웠지만 아래 그림과 같이 개요를 작성했습니다.

논문 작성 기간을 2주로 잡았었다니,, 정말 초보자인 게 티가 나죠 ? 사실 처음에는 국내 저널로 내려고 마음먹고 있었기 때문에 큰 부담은 없었습니다. 그치만 구현을 해보고 이것저것 해보다보니 해외 저널로 도전해보자는 교수님의 말씀이 저를 여기까지 오게 만들었습니다. 실제 계획했던 기한과는 차원이 다르죠.. 지금 이 글을 작성하는 날짜가 2023-12-04 랍니다..
어찌 됐든 위 계획했던 것을 토대로 시작을 했습니다. 저기 적혀있는 것처럼 6월 4주차에는 기본적인 개념을 다지고자 했습니다. 따라서 저는 CL을 DRL에 적용한 여러 가지 사례를 보여주는 survey 논문을 읽어봤습니다.
Curriculum Learning for Reinforcement Learning Domains: A Framework and Survey:
- Curriculum Learning 에 대한 모든 것
- 논문에서 제시하는 Framework를 사용하여 미결 문제 찾기
- RL , CL 연구를 위한 방향성 제시
What is Curriculum Learning ?
-> 인간 발달 , 정규 교육 등 보편적인 학습 방법
-> 연속적인 하위 게임에서 새로운 기술을 배우고 이전 게임에서 배운 지식을 바탕으로 달성해야하는 새로운 요소가 도입됨.
-> 학습을 가속화하거나 향상시키기 위해 에이전트가 시간이 지남에 따라 휙득하는 경험을 정렬하는 역할로 과거의 경험을 정리하는 일과, 목표에 대한 훈련을 통해 경험을 습득하는 일을 모두 포괄하는 일반적인 개념
Ex) 스포츠를 배울 때 교육 과정을 순차적으로 구성하고 구조화하는 것.
Ex) 체스에서 첫 번째는 이동, 승진 등을 학습. 두 번째는 환경에 왕 추가하여 왕 살려두는 목표. 세 번째는 완전한 체스
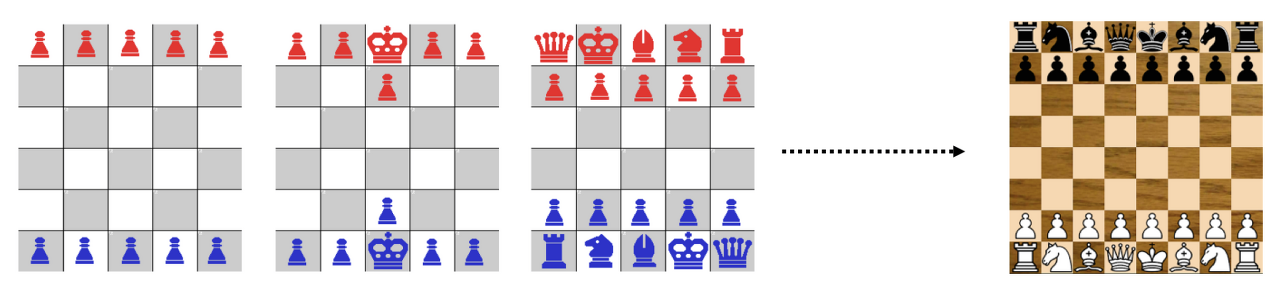
- 훈련 예제의 순서 중요
- 훈련 예제의 점진적 난이도
How can it be represented for reinforcement learning tasks?
- -> Automatic
- 경험 샘플에 대한 순서 (환경에서 얻는 경험들에 대한 순서)
- 작업을 학습해야 하는 순서 (목표 순서 , 환경에 대한)
- 전이학습 (reward, state 등이 다를 수 있으므로)
- -> Hand-operated
- 자동화시키지 않고, 직접 수동으로 다 해줘야함
- 커리큘럼을 설계하는데 시간, 노력 및 사전 지식이 엄청나게 사용되었는 지 평가하기 어려움
How can tasks be constructed for use in a curriculum ?
-> Intermediate task generation
- The primary challenge is how to sequence a set of tasks to improve learning speed
- useful source tasks to select from
- still rely on some human
- automatic or hand-operated
-> Curriculum representation
- 가장 일반적인 형태는 방향성 비순환 그래프
- 다대일, 일대다 및 다대다 작업에서 전이하는 전이 학습 방법
- single , sequence , graph
-> Transfer method
- 전이 학습 아이디어를 활용하여 커리큘럼의 작업 간에 지식을 전달
- 전달되는 지식 유형 : 전체 정책 , 가치 함수 , 전체 작업 모델 , 부분 정책 , 형성 보상 등
- 단일 작업의 샘플을 시퀸싱할 때 전이 학습 알고리즘이 필요하지 않음
-> Curriculum sequencer
- automatic
- domain expert
- user
-> Curriculum adaptivity
- 교육 전 정적 설계 : 도메인 및 가능한 학습 에이전트의 속성 사용
- 교육 중 동적 설계 (적응형) : 에이전트가 학습 중 직면한 목적에 관련된 속성의 영향을 받음
-> Evaluation metric
- 생성, 사용 비용은 매몰 비용으로 처리 -> 목표에 대한 성능에만 관심
- curriculum 중간 작업에 대한 비용이 고려됨 , 사람이 손으로 디자인한 경우 등
- 생성 비용과 교육 비용을 설명함
-> Application area
- 장난감
- sim 로봇
- real 로봇
- 비디오 게임
Curriculum Learning for Reinforcement Learning Agents
-> Task Generation
- 유익한 중간 작업을 만드는 것
- 모든 작업은 최종 작업과 관련이 있어야 함
- 작업 단순화 , 작업 차원 줄이기 , 높은 보상에 가까운 상태를 추가하여 초기 상태 세트 수정
- 실수가 감지되기 몇 단계 전으로 되감고 학습 재개
-> Sequencing
학습을 용이하게 하는 방법
작업 또는 샘플이 주어지면 순서대로 정렬하는 것.
ㄴ sample sequencing
- sample sequencing : 훈련 예제가 특정 순서로 학습자에게 제공됨
- 강화학습으로 예시를 들면 priority experience replay 하는 것.
- TD error , CI 함수를 이용하여 priority 구성 혹은 시퀸싱
- ScreenerNet , PER approach , HER, CHER , EBU
ㄴ Co-Learning
- 다중 에이전트 접근 방식
- TD-Gammon , AlphaGo , AlphaStar
- 협력적이거나 적대적으로 행동하여 새로운 행동의 습득을 촉진
- asymmetric self-play, RARL
- Ex) 숨바꼭질에서 찾는 에이전트와 숨는 에이전트 함께 학습
ㄴ Reward and Initial / Terminal state distribution changes
- 환경을 다르게 하는 것
- 총 쏘는 것이 목표일 때 초기 상태 분포를 목표 상태에 가깝게 시작하고 후속 작업에서 점진적으로 더 멀리 이동하여 학습할 수 있도록 일련의 작업을 만드는 것
- GAN , SAGG-RIAC
- 적응형 커리큘럼 학습 전략 : 에이전트가 현재 환경에서 잘 수행하면 확률 분포가 더 어려운 작업으로 이동
ㄴ No restrictions
① MDP/POMDP
- tasks 와 상호작용하는 에이전트와 tasks 를 선택해주는 에이전트로 나눔.
- 곡선 기울기의 절대값이 가장 높은 task 를 선택 , 추가 시간이 필요한 task 선택 등
② 시퀸스에 대한 조합 최적화
- 고정된 tasks가 주어지면 최상의 커리큘럼으로 이어지는 순열을 찾음. Ex) 블랙박스 최적화.
③ 방향성 비순환 작업 그래프
- 비순환 방향성 작업 그래프
- 한 노드에서 다른 노드로 향하는 edge 는 한 task가 다른 task의 원본임을 의미.
④ 중간 Task에 소요되는 시간
- 성능이 안정될 때까지 중간 Task에 대해 훈련
- 성능이 증가하면 CT가 증가하고, 성능이 감소하면 학습 속도를 느리게 하는 적응형
ㄴ Human-in-the-Loop curriculum 생성
- 현재까지 나온 것들은 시퀸싱 알고리즘을 사용하여 자동으로 커리큘럼을 생성하는 것
- 커리큘럼 설계에 접근하는 방법을 더 잘 이해하는 것이 중요
- 교육 일정을 나누어 각 기술들을 각각 학습할 수 있게 하는 것.
- 이때 발생되는 문제점은 직선 보행에서 속도를 빠르게 최적화 시켰는데 회전할 때 넘어지는 문제가 발생될 수 있어서 중첩 계층 학습이라는 아이디어를 활용
- SABL (Strategy-Aware Bayesian Learning)
-> Knowledge Transfer
- 어떤 task에서 학습한 지식을 재사용할 지
- 어떤 종류의 지식을 재사용할 지
- 에이전트의 유형에 따라 어떤 것을 적용할 지
- Ex) 전체 policy , 부분 policy , value function , model
What is Transfer Learning ?
- A를 학습시키기에 데이터가 부족할 때, 학습 데이터가 많은 B를 학습시켜 A를 해결하는 것. 이때 부분적으로 레이어를 변경하여 그 부분만 재훈련하는 방법
- 이미 사전에 학습된 모델을 이용하여 재사용할 레이어 수와 재교육할 레이어 수를 정함
- Deep Learning 을 활용하여 데이터 수 줄이기 혹은 학습 속도 개선
Curriculum Learning (CL) 정리
▣ 인간이 교육받고 성장하는 과정과 비슷한 원리
- 중등 수학 -> 고등 수학 -> 대학교 수학
- 여러 교육과정 중 선택해서 듣되 최종적으로는 모든 교육과정을 수강
▣ CL은 Task generation , Sequencing , Knowledge Transfer 총 세 가지의 중요한 구성 요소
- Task generation 는 유용한 중간 경험을 만드는 것
- Sequencing 는 학습을 용이하게 하는 방법
- Knowledge Transfer 는 다음 단계로 넘어갈 때 기존에 있던 지식 중 어떤 지식을 갖고 갈 지
▣ Task
- 작업을 달성했는 지를 평가하는 기준이 애매모호 함
- 학습했다는 기준을 어떤 것으로 해야할 지에 대한 고민
- 최적의 정책으로 수렴할 때까지 or Reward 평균 이상 등등
- 위 기준을 정해서 각 기준을 넘으면 다음 curriculum으로 넘어감
▣ Sequence
- Graph 와 Linear
- Graph : 정해진 순서는 없고 뒤죽박죽 학습함
- Linear : 정해진 순서에 따라 학습함

- 왼쪽 그림은 Linear sequences
- 오른쪽 그림은 Directed acyclic graphs in block dude.
▣ Environment
- 학습 전 미리 curriculum env 구성
- online 혹은 offline 가능
- online : 에이전트의 학습 진행 상황에 따라 에지가 동적으로 추가 됨. (Single task CL , Task level CL , Sequence CL)
- offline : 이미 정해져있는 에지를 선택하게 됨.
▣ Transfer Intelligence
- CL에서는 Transfer Learning 을 이용함
- 전체 정책 , 가치 함수 , 전체 작업 모델 , 부분 정책 , 형성 보상
- 특정 층 혹은 노드만 이전하는 경우도 있음.
- 입력 노드의 개수를 추가해주는 경우도 있음.
▣ Curriculum Learning 의 한계
- 유익하다는 것은 경험적으로 증명됐지만 curriculum 이 why , when 유용하고 how 만들어야하는 지 부족함
실제 적용할 때 주의사항
- 수동으로 할 것임
- Linear
- 각 curriculum 별로 난이도 조정
- 어떤 지식을 이전할 지
- offline or online
- Fine-Tuning 시 하이퍼 파라미터 조정
Refernce
- S. Narvekar, B. Peng, M. Leonetti, J. Sinapov, M. E. Taylor, and P.
Stone, ‘‘Curriculum Learning for Reinforcement Learning Domains:
A Framework and Survey’’ 2020, arXiv2003.04960. [Online].
Available: https://arxiv.org/abs/2003.04960
Curriculum Learning for Reinforcement Learning Domains: A Framework and Survey
Reinforcement learning (RL) is a popular paradigm for addressing sequential decision tasks in which the agent has only limited environmental feedback. Despite many advances over the past three decades, learning in many domains still requires a large amount
arxiv.org
여기까지가 6월 4주차에 공부한 내용입니다. 논문 읽는게 낯선 저한테는 50페이지 읽는 게 쉽지 않았다는,,,
7월 첫째주에는 실제 여러가지 방법으로 구현을 해봤답니다.
이 부분은 작성 후 링크로 남기겠습니다.
모든 대학원생 분들 존경하고 화이팅입니다.


