CNN : 인공 신경망 (ANN)의 한 종류로 , 흔히 이미지 인식 및 처리 (to analyze visual imagery)에 사용되고, CNN의 구조를 잘 보면 특정 자극에 대한 시각 피질의 뉴런 반응과 유사하다고 한다. _ Wikipedia
-> input -> padding -> convolution -> pooling -> convolution -> ㆍㆍㆍ -> flattening -> output
-> 특정 자극에 대한 시각 피질의 뉴런 반응을 인공적으로 유사하게 만든 신경망이라 이해하겠다.
-> +) 이미지에서 픽셀 단위 한 개가 중요한 게 아니라 어떤 뭉쳐있는 픽셀들이 특징점이 있는 것이므로 (개의 머리,몸통 등) convolution layer 할 때 filter, stride 를 잘 선정해주는 것으로 이해했다.
Convoultion : 합성곱 이라는데 합성곱이 뭘까.

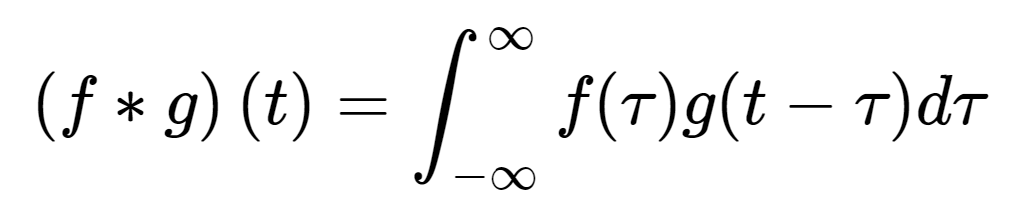
-> 이건 정의인데 convolution 계산과 어떤 게 연관되어 있는 건 지 잘 모르겠으니 일단 받아들이자. 적분한 값이 f * g 랑 같다고 한다.
Convolutional Layer : sliding window 방식으로 이동해가며 합성곱을 한다는데, 대응되는 숫자끼리 곱한 뒤 모든 숫자를 더해주면 된다고 한다. (필터를 stride 1로 convolution 한 결과가 특성임)


-> bias 도 넣는다고 함.
-> 이게 합성곱 식이랑 무슨 연관이 있는 지 모르겠지만 convolution 계산 원리는 알겠다.
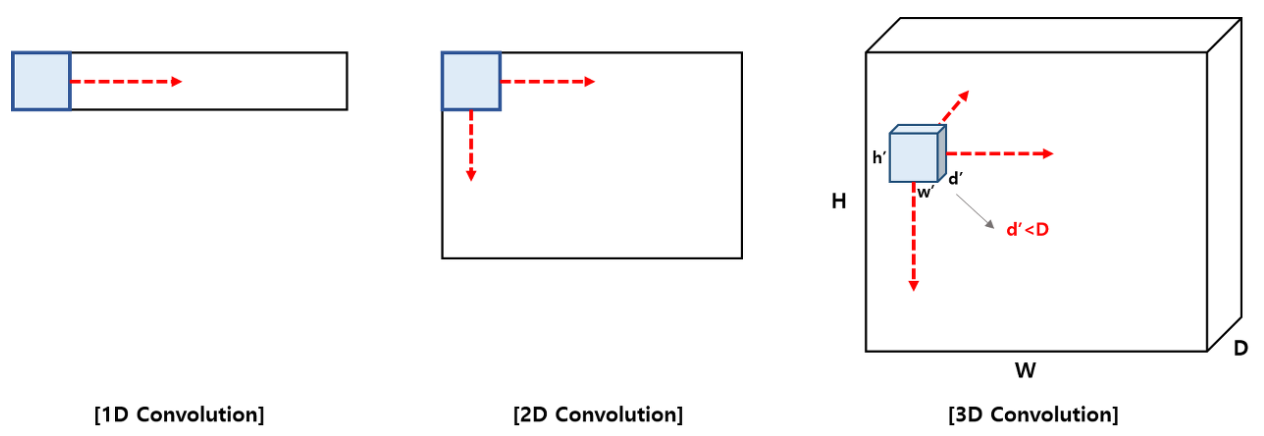
-> 이동하는 방향의 수에 다라서 1D, 2D, 3D 로 나뉜다고 함.
Stride : filter를 input에 적용할 때 움직이는 간격이라고 한다.

-> stride : 3 인 경우 stride가 4가 아니라 3이 맞는 건가 의문이 든다.
-> +) 게시글 작성자 분께서 stride 3 (x) stride 4 (o) 라고 답변해주셨다. 따라서 의문점 해결
Padding : 위에 그림에서 stride 1이라 가정했을 때, 끝까지 convolution 한다고 생각해봐요. 중심부는 4번 겹쳐지는데 모서리 부분은 더 적게 겹쳐지는 부분들이 있죠 ? 그러면 모든 정보를 공평하게 계산한게 아니죠. 따라서 padding 을 통해 이를 해결한다고 이해했어요.

-> 정보 손실도 그렇지만, convolution 할 수록 행렬 크기가 작아짐을 방지하는 것도 있다고 하네요.
Pooling Layer : convolution 이랑 무슨 차이인가 했더니만, pooling 은 filter를 이용해서 하는 게 아니라 그냥 그 입력 데이터 그 이미지 그 자체를 조금 덜 표현하는 대신에 크기를 조금 줄인 이미지 그런 느낌 ? 당연히 overfitting problem 해결도 어느정도 되겠지 ?

-> Max pooling , Average pooling 이 있는데 Max pooling 성능이 더 좋다고 함.
-> 어떤 데이터의 특징점들은 어느정도 유지하되, 그 데이터의 크기를 조금 줄이는 방법
Flattening Layer : flatterning layer의 목적은 어떤 특성이 추출되면 fully connected layer 로 추출된 이미지를 분류하기 위함이라고 한다.

-> convolution 하여 추출된 특징들을 neural network에 넣기 전에 형식 변환해주는 느낌으로 이해하겠다.
결론 :
- CNN 목적,원리는 이해했음
- Convolution 합성곱 이라는 단어가 와닿지 않아, 실제로 구현해보거나 수학적인 이해가 필요함.
- 위 정보를 쉽게 설명해주신 YJJo께 감사합니다.
Ex) 1D CNN
1차원 CNN은 주로 텍스트 분석, 시계열 분석을 하는데 주로 많이 사용된다고 함.
여기서 헷갈렸던 개념이 kernel_size와 filters의 개념인데
tensorflow model을 학습시킬 때 ,
위와 같은 형식으로 학습시키게 되어있다.
위의 경우 kernel_size가 4인 32개의 서로 다른 필터를 생성한다는 것임.
Reference
https://stackoverflow.com/questions/46503816/keras-conv1d-layer-parameters-filters-and-kernel-size
'About my life > Undergraduate Researcher' 카테고리의 다른 글
| [Journal] Outline (0) | 2023.06.26 |
|---|---|
| webots simulation DQN (0) | 2023.03.02 |
| Webots error (1) | 2023.02.14 |
| Present Path (0) | 2023.02.08 |
| Long Short-Term Memory (LSTM) (0) | 2023.02.06 |